之前写过一篇介绍字符和编码的文章:<程序中的字符和编码> http://blog.csdn.net/cc_net/archive/2008/09/07/2896317.aspx,主要是从理论上介绍了,当时对于unicode介绍的比较简单,而在c#中用的很多,写程序经常碰到编码问题,所以这次主要介绍一下编码规则。
一 编码和编码规则
这是一个比较不好理解的东西。我们都知道计算机只认识2进制的数字0和1,任何字符在电脑中都是以2进制的形式存储的。把字符转换为计算机认识的过程就叫做编码,经过编码的字符才能被计算机处理,这时经过编码后的字符称之为【内码】。从前面一篇文章可以看到字符编码经历了ASCII、ANSI、UNICODE这几个阶段。所以字符编码就是指定文字和内码之间转换的一种规则,更简单的可以理解为用几个字节去标识字符。而所以编码规则就是,字符在字节中的存储方式。 这个就好比邮政编码,有的国家是6位数,有的是5为数标识。对于6位数,那一位是表示省,那一个是表示市这是需要规定的,这也就是所以的编码规则。
二 BOM
在介绍UNICODE编码规则之前,需要先介绍一个概念,BOM——Byte Order Mark,就是字节序标记。因为USC-2和USC-4都是用多个字节来表示一个字符,所以就存在一个表示顺序的问题。是字节1+字节2表示,还是字节2+字节1来表示一个字符。
在UCS编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
看了上面的介绍,我们就可以在UNICODE编码前加上一个BOM,就可以知道用那一种方法解码字符。
三 UNICODE编码规则
对于UNICODE编码来说,在初期是有USC-2和USC-4两种编码方式,也就是使用2个字节和4个自己来存储字符。而UNICODE编码的编码规则叫做UTF(Unicode Transformation Format),目前存在的有UTF7,UTF8,UTF16和UTF32这几种。 其中UTF-16规则对应USC-2编码,而UTF-32规则对应USC-4编码。而UTF-7和UTF8比较特殊。
1.UTF-7
UTF-7 编码将 Unicode 字符表示为 7 位 ASCII 字符的序列。此编码支持某些需要它的协议,最常见的是电子邮件和新闻组协议。由于 UTF-7 不是特别安全或可靠,而且大多数现代系统都允许 8 位编码,因此 UTF-8 应优先于 UTF-7。
以上是MSDN对UTF-7的解释,我们可以看一个列子:
static void Main(string[] args)
{
String test = "1a好";
File.WriteAllText("c://test.txt", test, Encoding.UTF7);
}我们使用WinHex打开刚才的文本可以看到, 和ASCII一样,每个字符使用1个字节表示。而且无法表示和中午,后面的中文被解析为了对应的ASCII字符。
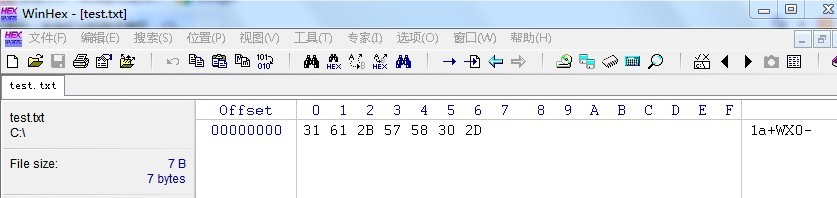
UTF-7作用是吧UNICODE字符转换为ASCII,所以他是按一个字节一个子集去解析的,但是不知道为什么中文对应5个字节。如果我们程序直接输出File.WriteAllText(“C://test.txt”, test, Encoding.ASCII);
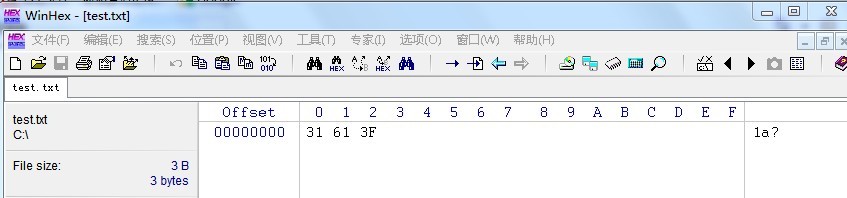
可以看到,世界只有3个字符,而且最后一个中文无法识别。
2 UTF-8
UTF-8 允许使用 8 位数据大小进行编码,可用在许多现有操作系统上。对于 ASCII 范围的字符,UTF-8 与 ASCII 编码相同,并且允许更宽的字符集。但是,对于 CJK 语言,UTF-8 可能要求每个字符使用三个字节,这样,数据大小可能超过 UTF-16。请注意,有时 ASCII 数据(如 HTML 标记)的数量正是 CJK 范围增大的数量。
以上是MSDN对UTF8的解释,我们还是看一下上面的列子,把编码格式修改为UFF8,在用WinHex查看:
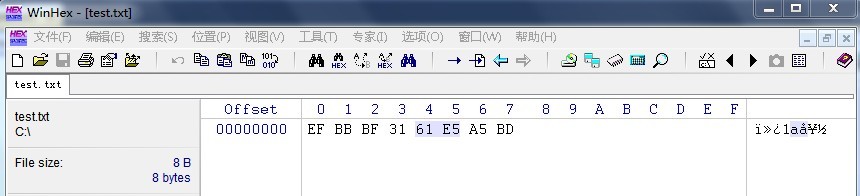
我们看到了【1】和【a】对应的编码【31】,【61】,而后面的【E5 A5 BD】对应的是中文的【好】字的UTF8编码。而在整个字符前多出了3个字符【EF BB BF】。这个和我们前面介绍的BOM很像。我们在一下有关的定义:
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。Windows就是使用BOM来标记文本文件的编码方式的。
而我们注意到,在C#中,对于UTF-8的BOM有几种不同编码方式。从MSDN上可以看到3个有关的构造函数。其中一个如下:
public UTF8Encoding(
bool encoderShouldEmitUTF8Identifier,
bool throwOnInvalidBytes
)参数指定是否提供 Unicode 字节顺序标记,以及是否在检测到无效的编码时引发异常。也就是我们可以指定编码时是否带有BOM。
3 UTF-16
UTF-16在.NET中对应的是UnicodeEncoding类,一下是MSDN的介绍:
编码器可以使用 Big-Endian 字节顺序(从最高有效字节开始),也可以使用 Little-Endian 字节顺序(从最低有效字节开始)。例如,大写拉丁字母 A(码位为 U+0041)的序列化结果(十六进制)如下所示:
- Big-endian 字节顺序:00 00 00 41
- Little-endian 字节顺序:41 00 00 00
通常,使用本机字节顺序存储 Unicode 字符的效率更高。例如,在 Little-endian 平台(如 Intel 计算机)上最好使用 Little-endian 字节顺序。
与UTF-8不同,这里BOM有用的,所以对应了多个构造函数,其中一个如下
public UnicodeEncoding(
bool bigEndian,
bool byteOrderMark,
bool throwOnInvalidBytes
)参数指定是否使用 Big-Endian 字节顺序,是否提供 Unicode 字节顺序标记,以及当检测到无效编码时是否引发异常。

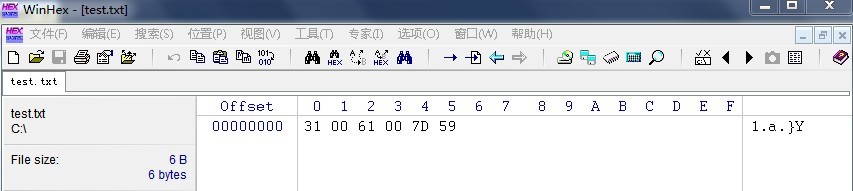
上面2个图是是否使用Big-Endian的区别。但是他们都没有携带BOM。下图是使用了BOM标记。

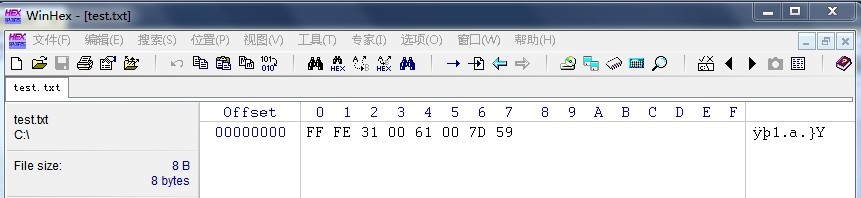
通过2个图的对比,正如前面说的【FFFE】表示这是一个BE,而[FEFF]表示LE。
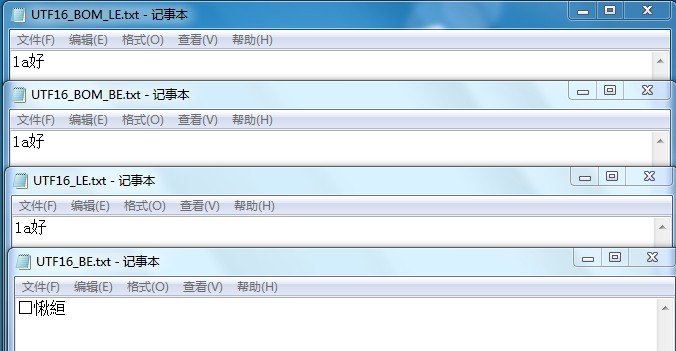
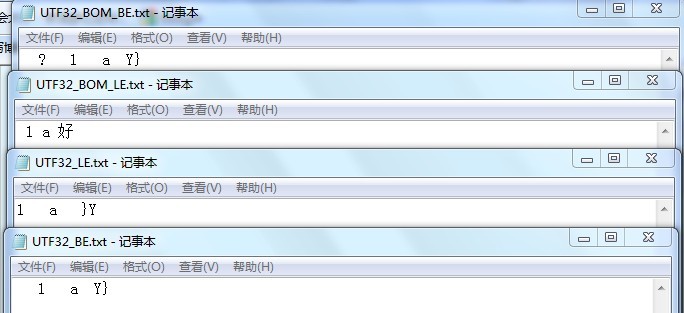
但是用记事本打开的时候却发现了问题,当保存不带BOM的BE格式,windows记事本无法解析了。因为WINDOWS默认是使用带BOM的LE格式,对于没有携带BOM信息的,为LE时按默认去解析,所以BE时就解析出错了。而用Notepad+打开,也是一样。但用UE打开时,只能识别带BOM的LE格式。
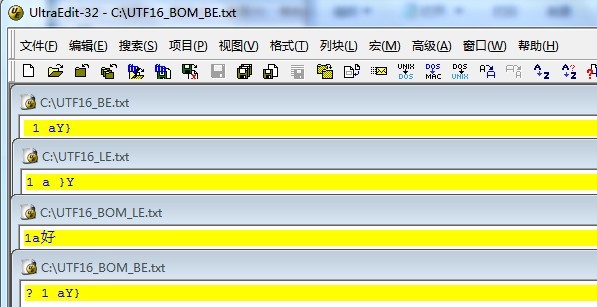 、
、
从上面的结论可以看出,不同的文本工具读取文本方式是不同的。这一点必须注意。在WINDOWS平台上,最好使用BOM的LE格式。获得对各种编辑器最好的兼容性。
4 UTF-32
UTF-32和UTF-16基本一样,不同的是他使用4个字节表示一个字符。我们把上面的情况修改为用UTF-32编码输出,在WinHex中可以发现,结构和UFT-16一样,只不过每个字符是4个字节,而【FFFE】也变为了【FFFE 0000】,而【FEFF】则变为了【0000 FEFF】。
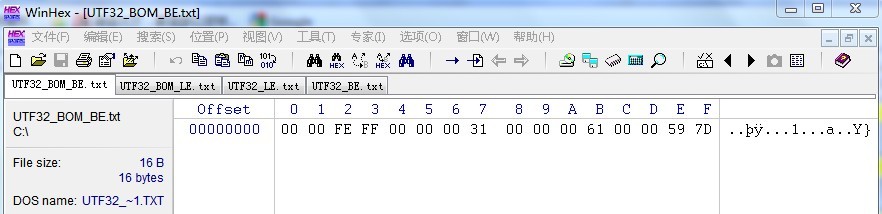
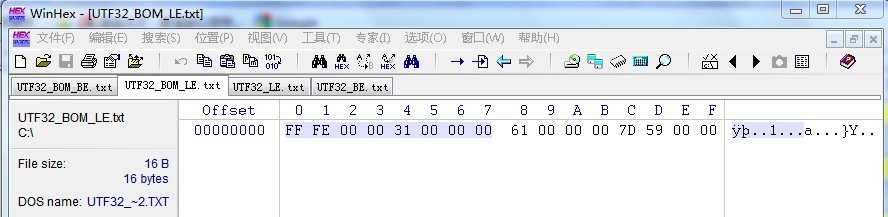
这里省略了不带BOM的情况,而我们尝试用记事本,NotePad+已经UE,都无法正确的现实文本内容。
其中到BOM_LE格式时,可以显示,却是当作UTF16格式解析的,因为多出的2个字节00被解析为了空格。而用Notepad+打开会发现,多出的00字节被显示为【NULL】。而同样无法正确显示。
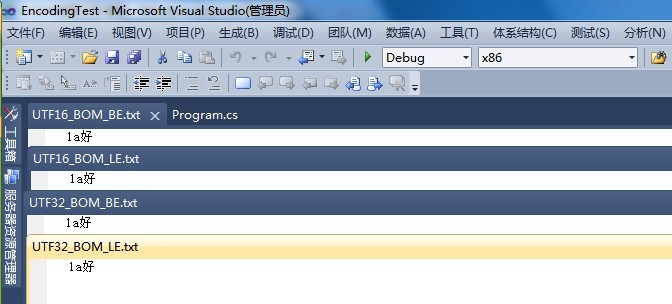
这个时候我们突然想到了VS,于是我们用VS打开,发现VS能正确显示带BOM的UTF-32和UTF-16格式的文本。而对于不带BOM信息的则无法打开。(VS2010可以吧每个标签页脱下来,方便代码对比,确实很不错)
四 UTF-8的补充
UTF-16和UTF-32的一个缺点就是它们固定使用两个或四个字节,这样在表示纯ASCII文件时会有很多00字节,造成浪费。而RFC3629定义的UTF-8则解决了这个问题。而补充的主要是BOM和记事本解析的内容。
对于UTF8老师BOM不是必须的,所以当你的编码带有UTF-8的BOM时,记事本就会安把其中内容按照UTF8来解析。那么他又是怎么区分出到底是一个字节表示一个字符还是三个呢?其实对于UTF8,不同的字节数编码方式是不一样的。对于1个字符来说,他的每个字节是以【0】开头;而对于2个字节表示的字符,第一个字节是以【110】开头,第二个字节是以【10】开头;具体见下面的表格:
UCS-2 (UCS-4) 位序列 第一字节 第二字节 第三字节 第四字节 U+0000 .. U+007F 00000000-0xxxxxxx 0xxxxxxx U+0080 .. U+07FF 00000xxx-xxyyyyyy 110xxxxx 10yyyyyy U+0800 .. U+FFFF xxxxyyyy-yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz U+10000..U+10FFFF 00000000-000wwwxx-
xxxxyyyy-yyzzzzzzz11110www 10xxxxxx 10yyyyyy 10zzzzzz
对于没有携带BOM时,记事本是通过对每个字符的编码进行分析来确定她的编码方式。这里可以做一个测试。写入2个不带BOM的文本。并选择另存为:
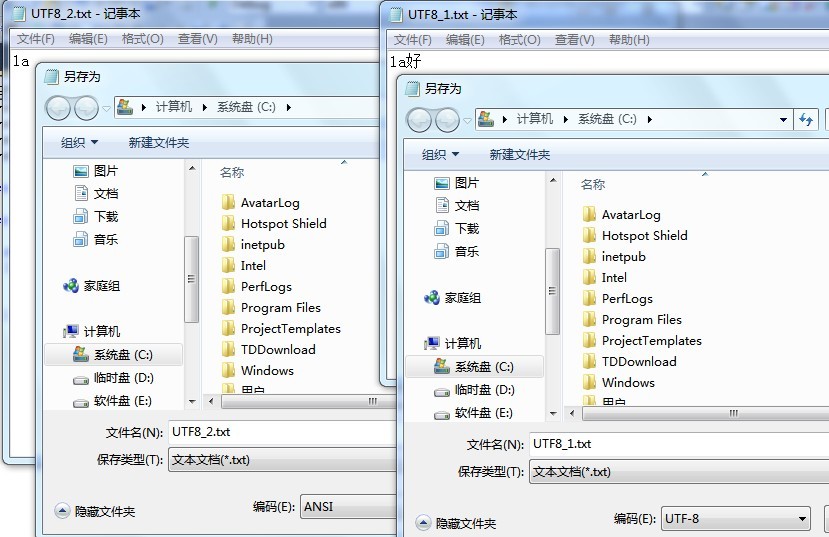
我们可以看到,没有携带BOM信息时,记事本是根据字符编码来判断编码格式,对于全部都是ASCII字符的情况,记事本把他当做了ANSI编码而不是UTF-8(注意这里的ANSI包括ASCII和ANSI编码,因为一个字节时,最高位也是0和ASCII一样)。而对以包含有一个中文字的,则被正确的认识成了UTF-8。所以我们在.NET中,要输出的只有英文字符和数字等ASCII能表示的字符,我们可以使用不带BOM的UTF-8格式,而非ASCII或则UTF-7编码。
下面是摘抄与MSDN上有关选择编码的一段话:
当您有机会选择编码时,强烈建议您使用 Unicode 编码,通常为 UTF8Encoding 或 UnicodeEncoding(也支持 UTF32Encoding)。 尤其需要指出的是, UTF8Encoding 比 ASCIIEncoding 更为可取。 如果内容是 ASCII,则这两种编码是相同的,但 UTF8Encoding 还可以表示每个 Unicode 字符,而 ASCIIEncoding 仅支持介于 U+0000 和 U+007F 之间的 Unicode 字符值。 因为 ASCIIEncoding 不提供错误检测,所以从安全角度来看, UTF8Encoding 也更好些。
UTF8Encoding 已经过优化以尽可能提高速度,它应比任何其他编码更快速。 即使对于完全采用 ASCII 的内容,使用 UTF8Encoding 执行的操作也比使用 ASCIIEncoding 执行的操作速度更快。 只有对某些旧式应用程序,才应考虑使用 ASCIIEncoding。 但即使在这种情况下, UTF8Encoding 可能仍然是一种更好的选择。 假定采用默认设置,将会出现以下情形:
- 如果应用程序具有并非严格采用 ASCII 的内容,并使用 ASCIIEncoding 对其进行编码,则每个非 ASCII 字符都将被编码成一个问号(“?”)。 如果应用程序随后对此数据进行解码,将会丢失信息。
- 如果应用程序具有并非严格采用 ASCII 的内容,并使用 UTF8Encoding 对其进行编码,那么在将结果解释为 ASCII 时,结果看起来是不可理解的。 但如果应用程序随后对此数据进行解码,数据能够成功还原。
五 其他
在.NET中,提供了编码的一种转换,也就是Encoding Convert 对字节数组进行编码转换。这个方法可能跑出异常中出现了2个回退相关的异常。
如果应用程序尝试对字符进行编码或解码,但不存在相应的映射,则应用程序必须实施回退策略(这是一种失败处理机制)。有两种类型的回退策略:
- 最佳回退:当字符在目标编码/解码中不具有精确匹配时,应用程序可以尝试将它们映射到类似的字符。
- 替换字符串:回退如果不存在合适的类似字符,则应用程序可以指定替换字符串。
以上是MSDN上对回退的解释。其中也提到,我们应该使用UTF格式的编码,来避免回退的发声,因为UNICODE可以表示所有的字符。而对于ACSII编码或者ASNI编码,在需要处理回退时,如果字符不能精确映射,请总是使用 EncoderReplacementFallback 和 DecoderReplacementFallback 来取代替换字符串。关于回退的处理和势力,我从来都没有使用过,就不在多言,但是MSDN上相关的4个类都有示例。
总的说,关于字符和编码还是有许多知识点,平时在使用中都只是用,而不知道为什么用,应该如何用,其中UTF-7,以及UTF8和ACSII之间的选择都不是太清楚。另外要注意的是,在.NET中有一些文本写入的方法,但是有的默认带有BOM,有的不带有BOM,这个是需要注意的,特别是在以UTF8格式写入ASCII,并且和其他ASNI编码的程序交互时可能就存在问题。而一般UTF-16以及UTF-32默认都是提供携带BOM信息LE格式的方式。


very good!