前端时间在一个.NET和C通信的接口测试中发现一个问题,由.NET发送到C的中文字显示是问号。应该是编 码的问题,但是具体是什么原因呢?自己不太清楚,然后找了一些相关资料看了下,总算对字符和编码有了 一定了解。
一 简单的程序
string msg = "欢 迎访问cc_net";
int l1 = System.Text.Encoding.Default.GetByteCount (msg);
int l2 = System.Text.Encoding.ASCII.GetByteCount (msg);
int l3 = System.Text.Encoding.Unicode.GetByteCount (msg);
int l4 = System.Text.Encoding.UTF8.GetByteCount (msg);
int l5 = System.Text.Encoding.BigEndianUnicode.GetByt eCount(msg);
int l6 = System.Text.Encoding.UTF32.GetByteCount (msg);
int l7 = msg.Length;以上是一段计算字符串长度的信息 。你能准确说出他们的值吗?? 下面是他们的实际结果
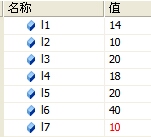
是不是感觉结果有些意外?这里简单讲下,l7是string.Length属性,他实际是获得string中char的个数, 所以是10。而其他几个都用的是GetByte方法,这个方法是活的字符穿的字节数。前面使用了Encoding来指定 编码格式。所以这里是获取这个字符串在不同编码下的字节数。我们暂时不去管以上结果为什什么是那么多,只是从上面可以知道不同字符串可以用不同编码标识,而且 得到的字节长度是不同的;另外就是字符和字节是不同的概念,长度也是不同的。
二 计算机中的字符
我们知道计算机只认识2进制,所以无论什么字符在计算机中都是用2进制来表示的。所以任何信息要存储 在计算机中,都必须使用一定规则,让他变为2进制存储在计算机中。所以每个中文字符,英文字符还有符号 字符,在计算机中都有各自对应的2进制编码来表示。
1:字符和字节
字节我们都很清楚,计算机中用8位2进制来表示一个字节(1Byte = 8bits)。而字符也很好理解,在编 程语言中,通常用char来便是一个字符,诸如’a’,’b’,’c’,’/’ 这些就是一个字符。我们输入一个字符,但计 算机不认识,所以她必须转换为2进制。所以,可以说字符(char)是通过字节(Byte)存储在计算机中的。 那么一个字符用多少个字节来存储呢?这就引出了编码。
2:字符编码
所谓字符编码,实际就是把字符按照一定规则转换成二进制编码存储在字节中。比如字符’a‘ 经 过编码后存在一个字节中表示为‘00110001’。而不同的字符转换的二进制编码是不同的。这样就可以标识 所有的字符了。我们把计算机内部标识编码也较为内码。
下面介绍下编码的发展:
在计算机刚出现的时候,使用的是英文,使用最多的就是ASCII码。它是一种把英文字符转换为计算机内 码的编码方式,它使用一个字节来存储一个字符。但是随着计算机发展,各种语言都使用上了,一个字节已 经不能够表示各个国家的所有字符了,所以出现了ANSI编码,也称为本地化编码,她使用一个或多个字节存 储一个字符,她最多可以表示6W多个字符,已经足够各国自己使用了。但随着网络的发展,各种语言的交流 使得ANSI码难以应付,因为,各国之间都使用自己的编码来表示各自国家的字符。就可能出现同一个二进制 编码,在不同语言中,显示的字符不相同,或是显示乱码,所以就出现了Unicode编码,也称国际化编码,她 那各国的编码统一起来,让每个国家的字符都有唯一的编码,保证了跨平台和跨语言。
| 系统内码 | 说明 | 系统 | |
| 阶段一 | ASCII | 计算机刚开始只支持英语,其它语言不能够在计算机上存储和显示。 | 英文 DOS |
| 阶段二 | ANSI编码 (本地 化) |
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由 此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码 方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下, ANSI 编码代表 JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两 种语言的文字,存储在同一段 ANSI 编码的文本中。 |
中文 DOS,中文 Windows 95/98,日文 Windows 95/98 |
| 阶段三 | UNICODE (国际化) |
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字 符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。 | Windows NT/2000/XP,Linux,Java,.NET |
3:字符集和编码存储标准
在ANSI编码中,各个国家只定义了自己国家字符如何表示,比如汉字编码中就没有定义如很存储日本和韩 文,所以他们的字符在中文系统中就无法正常显示。
所谓字符集,就是字符的集合。汉字很多,但并不是所有的汉字全部进行了编码,我们把常用的汉字进行 编码,所有这些编码的汉字的集合就是字符集。目前我们汉字主要有GB2312,BIG5,GBK等常用字符集,GB2312 只支持简体中文,而BIG5中就加入了对繁体中文的支持。所以使用不同字符集,包含字符不同,这就是为什 么有些字我们电脑显示不出来,而有些电脑显示的出来。
一般而言,字符集和编码是同时制定的,对于Unicode字符集而言,他又有多种存储标准比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等。这里存储标准和前面的编码还有所不同,编码是指用几个 字节来存,用那些字节那存储。而编码存储标准则是针对编码在计算机中是如何存放的。具体在Unicode中介 绍。
三 程序中的字符与编码
对于字节,字符以及编码的有了一定了解后我们就看看我们使用的程序中的字符。在C,C++,java和.NET中 都是采用char来标识字符,不同的是他们的编码是不同的。在C和C++中是采用ANSI编码,而JAVA和.NET中使用 的是Unciode编码。也就是说在C和C++中一个char是一个Byte,而在.NET中一个char两个Byte来表示的,而 在.NET和JAVA中是有专门的byte数据类型的。当然在C++中未来使用unicode编码,引入了wchar_t宽字符,而 且我们知道标准C++中是没有string类型的都是用char[ ]来保存ANSI字符串,而用wchar_t[ ]来表示Unicode 字符串。
一开始我提到了在发现.NET发给C的字符串,其中中文显示的是乱码,后来发现程序中错误的使用了ASCII 编码,因为ASCII编码无法标识汉字而且只能保存一个字节,所以穿入C中就无法显示了。如果采用下面两种 方式,在C语言中就可以正确显示。其中要说的是Default编码,他是采用了GBK字符编码,因为在中文XP系统中 ,默认的是使用GBK编码的,也可以使用指定的代码页编号或名称进行转换,如最后一条.
这里要注意的是.NET中Ecoding类是针对Unicode字符转换为二进制,也就是处理的字符必须是Unicode字符;如果您的应用程序必须将任意二进制数据编码为文本,则该应用程序应使用由 System.Convert.ToBase64CharArray 之类的方法实现的协议(如 uuencode)。
Byte[] data = System.Text.Encoding.ASCII.GetBytes (message);
Byte[] data = System.Text.Encoding.Default.GetBytes (message);
Byte[] data = System.Text.Encoding.Unicode.GetBytes (message);
Byte[] data = System.Text.Encoding.GetEncoding ("GB2312").GetBytes(message);上面提到了代码页的概念,代码页实际上是Windows为不同的字符编码方案所分配的一个数字编号,.NET支持的代码 页,具体可以查看MSDN中的Econding类。所以我们在编程平台间通信的程序时一定要注意编码的区别。
所以目前我们可以 知道Default编码时中文是2个字节,英文1个字节,所以l1 = 14;而用ASCII编码时,它都无法表示汉字,所 以每个字符都是一个字节表示,所以l2 = 10;
四 Unicode编码
Unicode编码是为 了方便跨平台,跨语言而产生的。它整合全世界语言的字符。任何文字在Unicode中都对应一个值,这个值称 为代码点(code point),代码点的值通常写成 U+ABCD 的格式。这样的话即便你是在日文平台下开发的程 序,只要你使用的是Unicode编码,那么在任何支持Unicode编码的平台上都可以正确显示出它的字符。
在初期,Unicode支持USC-2和USC-4两种编码方式。UCS-2是用两个字节来 表示代码点,其取值范围为 U+0000~U+FFFF。后来为了能表示更多的文字,人们又提出了UCS-4,即用四个 字节表示代码点。它的范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的。
前面提到过编码,编码是规定了代码点和文字之间的对应关系,而编码标 准则定义了这些编码在计算机中如何存储。规定存储方式的称为UTF(Unicode Transformation Format),其中应用较多的就是UTF-16和UTF-8了。UTF-8是动态编码,汉字基本是3个字节标 识,英文一个字符,所以前面程序中UTF-8时l4 = 18; 而Unicode编码(实际就是UTF-16)时,所有字符都使用2个 字节,所以l3 = 20 ; 而BigEndianUnicode(UTF-16)编码时l5 = 20,也是采用UTF-16编 码;这是因为UTF-16使用两个字节。我们都知道计算机中存储是有高低地址之分的,2个字节那个存在高位, 那个存在地位就是个问题,所以在UTF-16中就有了BE,LE和不带BOM的3种存储方式。具体这里就不讲了,有兴 趣自己看参考资料。对于UTF-32也存在这个问题,UTF-32是每个字符4个字节标识,所以l6 = 40;
Unicode这里的编码方式和存储方式比较复杂,在网上看的 意思也都不太统一,USC有的说是编码方式,有的说是字符集;UTF有的说是存储方式,有的说是USC的扩展,我也 弄不清楚,无从考证啊,所以我就不深 究了,大概了解下就可以了。如果有了解这些的朋友也可以留言告诉我。
参考资料:

