说到源码管理,CVS,VSS,SVN,TFS大家在公司可能都用的比较多了。但是在公司的环境基本都是在局域网中或者是专线连结到远程服务器来使用。平时自己在家和朋友一些写一些代码的时候都苦于没有代码管理工具,没有网络环境,而不能不把代码传来传去,很是麻烦。不过Google code提供了免费的SVN空间,主要注册了GMAIL,然后就可以使用SVN进行源码管理,和其他人共同开发了。网上有介绍的,不过我看了都不怎么详细,自己摸索了下,写下来大家分享下。
一 访问Google code
Google code的地址是 http://code.google.com/ ,如果使用cn去访问好像访问不了,我这里是一片空白。管理项目的话可以直接使用http://code.google.com/hosting/ 地址访问。用Gmail登录进去,页面的中间有【Create a new project 】,点击以后就可以创建项目了。
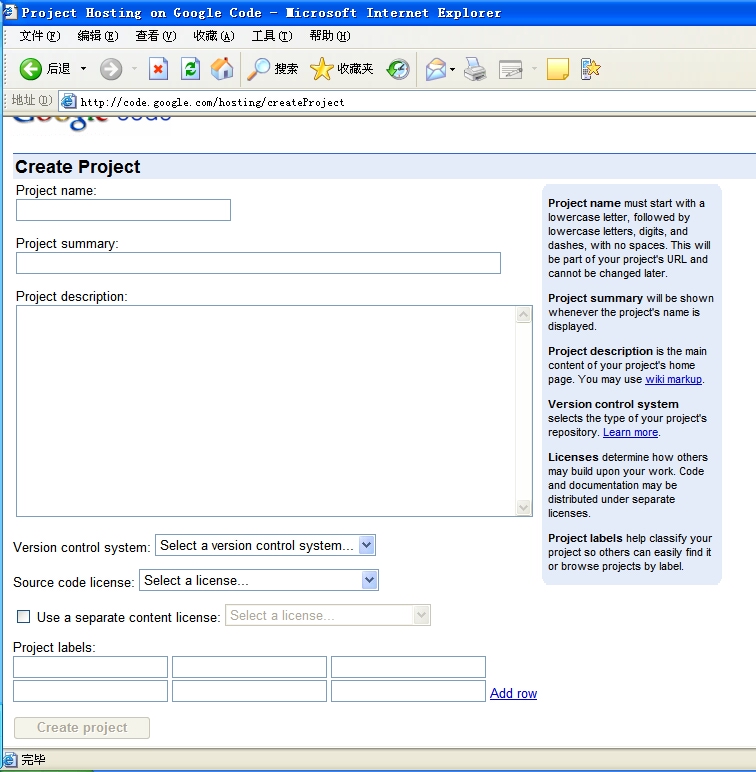
二 创建自己的项目
在创建项目的页面,填写项目名,概要和描述,其中项目名开头要小写,还不能有空格和其他符号。然后就是选择版本管理系统,证书等等,这些我也不懂,随便选吧,反正这有选好了,【Create Project】才可用。这里要注意的是项目名字可能冲突。如果创建成功就可以进入项目管理界面
三 项目管理
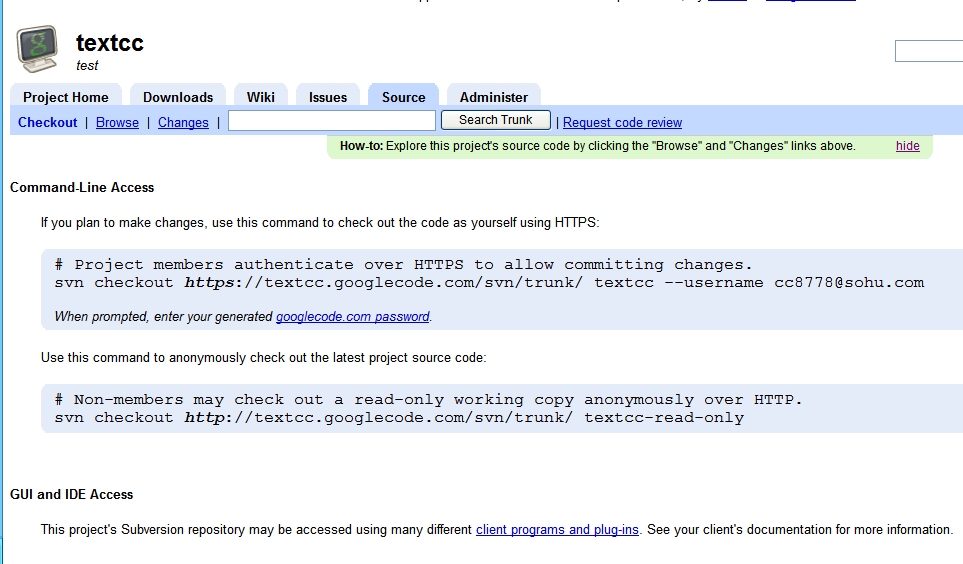
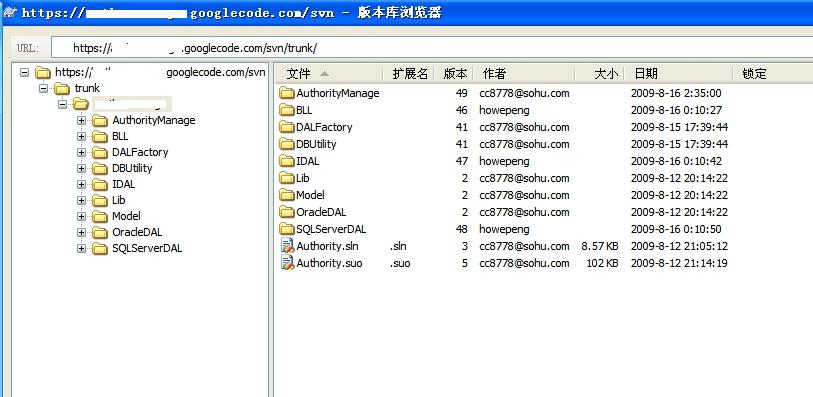
项目管理中,上方的菜单【Project Home】可以看到项目的概述和描述。点击【Source】就可以进行源码的管理。其中有2个地址,一个是Https开头的,一个是http的,https开头的是带加密的,所以如果要commit新的代码的时候就需要使用这个地址。而如果仅仅是取得代码可以只使用http开头的地址。
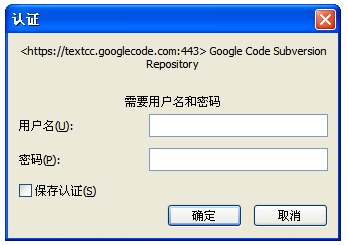
使用https的地址的时候需要提供用户名和密码,这里的用户名是Gmail的用户名,而密码是Google给每个项目生成的,而非是Gmail的密码。点击【When prompted, enter your generated googlecode.com password 】后面的蓝色连接可以看到密码。这个密码是你所有项目的密码,而不是每个项目一个密码。
四 用户管理
项目建立好以后就可以把其他人加入到项目中,这样就可以共同开发了。首先点击上方的【Administer】,然后点【Project members】,在下面填入要加入的用户Gmail就可以了。有Project owners,Project committers,Project contributors。具体解释右侧都有。点击保存后,其他用户登录后,在右上方的【My Favorite】下就可以看到自己加入的项目了。然后按三中介绍的方法找到密码。
五 其他管理
Google Code还提供了wiki等功能,我没用上,所以不是太了解。
六 安装客户端和VS插件
上面的工作做好后就是上传源码和文档。但是我找了半天也不知道怎么上传。以为是直接网页上上传,原来也要安装SVN客户端。在这里
http://tortoisesvn.net/downloads 可以下载到最新的TortoiseSVN,这个应该是目前用的最多的SVN客户端软件了。E文不好的朋友上面还提供了中文语言包。
安装完客户端后需要重启电脑,然后就可以远程连接到SVN服务器了。其中URL就填写Google 提供的哪个https的URL地址,然后填写用户名(Gmail)和密码(项目密码),保存后就OK了。客户端可以支持连接多个URL,每次启动的时候可以选择要连接到那一个。
支持SVN的VS插件我使用的是AnkhSvn,http://ankhsvn.open.collab.net/servlets/ProjectDocumentList?folderID=198 这里可以下载到最新版本。目前可以支持到VS2010,之前使用老版本对VS2008支持不好,文件状态不对,而且不能提交,换到最新版的时候就好了。安装的时候配置VS要比较长时间,不要以为是死掉了。如果只安装AnkhSvn而不安装TortoiseSVN也是可以的,不过你在VS中会发现,操作的功能少了很多,比如分支,合并等等。
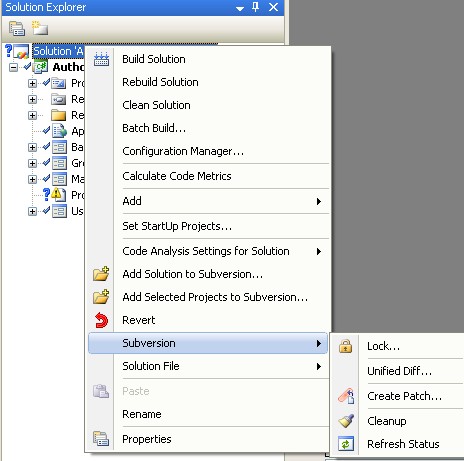
七 使用VS进行开发和源码管理
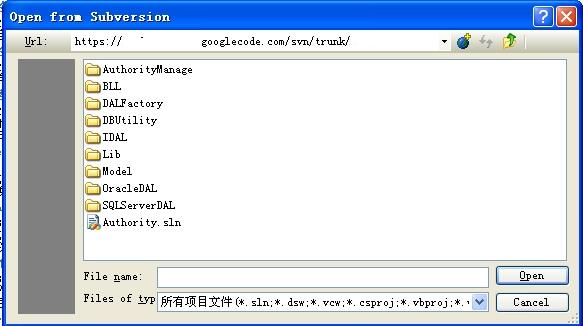
进入到VS中,打开【工具】–【选项】–【Source Control】,默认应该是已经配置好了为AnkhSvn。然后可以点击【文件】-【Subvwrsion】打开服务器上的源码。和其他工具一样,要选择一个本地路径来保存。
1:文件状态介绍
蓝色小勾:Check out状态;橙色小勾:文件被修改状态;橙色小方块:文件修改被保存;加号:新添加文件。
2:SNV版本控制
和VSS不同的时,VSS默认是锁住的状态,需要手动Check Out,而SVN是自动Check Out。那么这样不是会有冲突吗,其实这个和VSS允许多人牵出是一样的。在你Commit的时候,会检查版本,会自动合并或提示冲突或是版本过期等等。
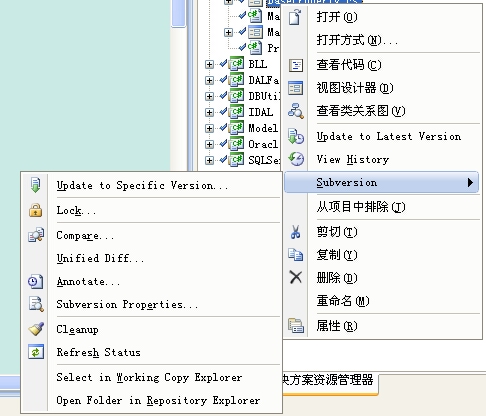
- 获取最新代码:这个不用说了就是从服务器上拿最新代码,但是如果你修改了文件,然后拉最新代码,这个时候系统会自动吧你修改的不部分和最新代码进行合并,如果有冲突会提示,要修修改冲突。
- 获取指定版本代码:这个可以通过查看历史,或者指定版本号来拉去指定版本的代码。这是同样会合并代码。需要注意的是,SVN的版本号和VSS不同,是全局版本号,而不是每个文件有一个版本号。这个要特别注意,因为你会发现一个文件版本号可能是跳跃的。
- Switch:有这样一个功能,可以把当前版本切换为制定的版本,和获取指定版本不同,他也会自动合并不同的地方。
- Revert:恢复功能,恢复到修改前的状态。这个要注意的是,如果你对文件修改,然后获取了最新代码,然后恢复,这个时候是恢复到最新版本,而不是修改前的那个版本。这点要注意
- 版本冲突:这里版本冲突有2种情况,如果你当前版本为1,服务器版本为2,你修改或提交,服务器会提示你本地版本过期了,你可以拉最新代码,并解决冲突后再次提交;如果你当前版本为2,服务器版本为2,而你从服务器获取版本1的代码,修改后,然后提交,这个时候是不会提示版本过期的,会覆盖掉服务器上的版本2,而成为版本3。这样是会冲掉代码的。
- 锁:SVN提供了锁的功能,就和VSS的单用户Check out是一样的,不能同时修改。但是目前Google Svn不提供锁的功能,所以没有办法使用了。
八 SVN资料
以前没有使用过SVN的源码管理,所以有些地方感觉不一样。关于SVN的版本控制的方法和SVN介绍可以参考一下网站
http://www.subversion.org.cn/svnbook/1.4/svn.basic.vsn-models.html